Explainable artificial intelligence and Semantic Web tools - Part 1
Posted on 2022-12-15 by Anabasis
Translations: frCategories: Technology
Explainable artificial intelligence is one of the foundations of the solutions developed by Anabasis. Like all artificial intelligence (AI) techniques, explainable AI seeks to simulate human intelligence (understood here as the ability to reason to a conclusion) by a machine. While other techniques are based on a machine metaphor of the physical support of this intelligence, like the brain, with for example the artificial neural networks and all its derivatives, explainable AI focuses on the abstract mechanisms of reasoning, their mathematization with formal logic, and their implementation by machines. Its explicability comes from its logical roots guaranteeing the correctness of its conclusions and their reliability.
This type of AI was proposed very early on with the emergence of expert systems in the late 1960s followed by a strong explosion in the 1970s. One example is the MYCIN project which started in 1972. An expert system is a tool that is intended to substitute for a specialist in a field of expertise. Rule-based expert systems allow a problem to be expressed in logical terms: from a set of initial truths (facts) and logical rules (business knowledge), the system infers new deductible knowledge with the aim of solving the problem. These systems were given a new lease of life in the early 2000s with the advent of the semantic web, a term coined by Tim Berners-Lee, whose objective is to add structured data sources for machines to traditional web pages intended for Internet users. This revival has been accompanied by the definition of new standards, some of whose acronyms readers will surely have already come across: RDF, RDFS, OWL, SPARQL, SWRL, RIF, etc.
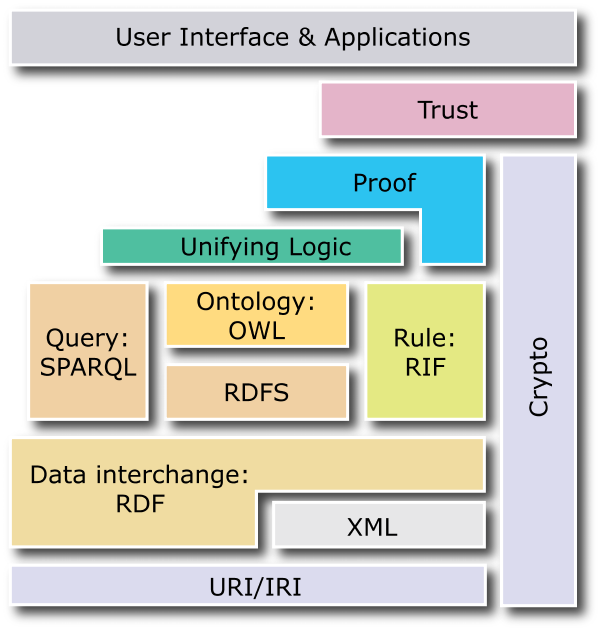
We propose a series of posts to describe this universe and how these artificial intelligence technologies allow us to switch from traditional information systems to intelligent information systems. We will cover the general ideas with a few technical forays for illustration. To satisfy the curiosity of those who want to go further, important links will be mentioned. For this first part, we will discuss knowledge graphs and their use as a database model.
Knowledge and graphs
Although the buzz word of the moment is data, what really interests us is the ability to recover information and knowledge from it. If one dismisses (with an admittedly easy brush-off) the problem of data analysis, there remains the question of representation with the goal of exploiting the knowledge acquired.
Knowledge representation is the field in which we seek to develop tools for communicating and sharing a body of knowledge. These tools are of very varied natures because this field does not only concern computer science; drawings, plans, maps, taxonomies, classifications, thesauri and other mind maps are all proposals that fall within the framework of knowledge representation. We will focus on formalised representations, therefore accessible to machines, such as semantic networks [A] or conceptual graphs [B,C]. More specifically, we will talk about knowledge graphs.
The founding idea of knowledge graphs is to use a graph to convey knowledge. Mathematically speaking, there are many kinds of graphs: multi-graphs, hyper-graphs, directed or undirected graphs, acyclic graphs, trees, forests, … You can do whatever you want. However, all these kinds of graph have in common that a graph is basically a collection of nodes and links between these nodes. In the case of knowledge graphs, given a universe we wish to represent (business knowledge, system models, the characters of the Simpson family, etc.), the nodes will be abstractions of the atoms of this universe and the arrows between pairs of nodes will embody the semantic relations existing between these different atoms. Here is an example:
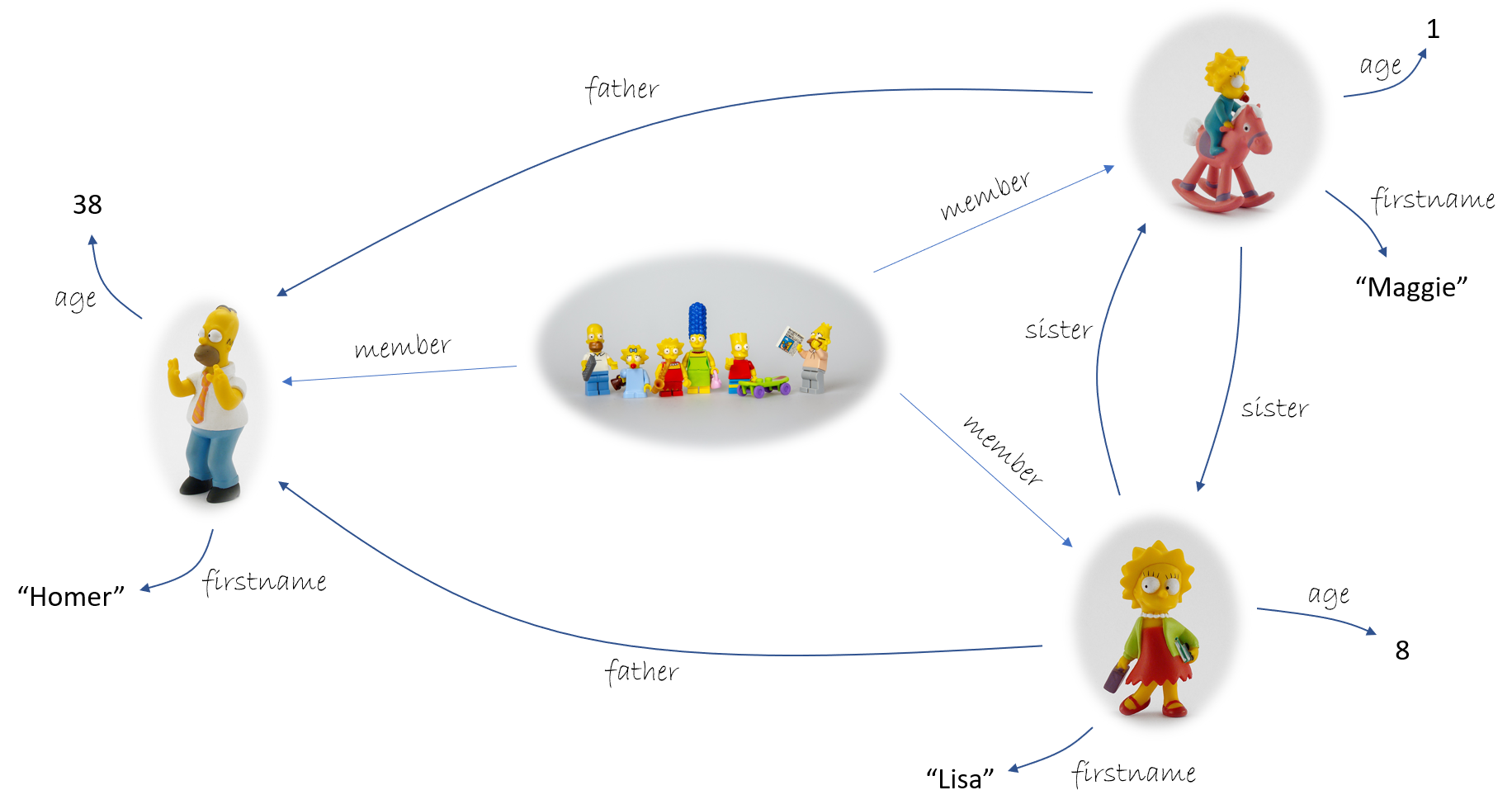
Triples at the Simpson's
Among the many data structures for capturing these knowledge graphs, one is to use an arc as the primary building block. This view is the one promoted by the RDF standard. The graph is constructed as a collection of arcs called triples, each of the form
< subject predicate object >
and creating an arc from a subject node to an object node, and decorated by the relationship between these nodes called a predicate. Here are some triples from the previous graphical representation:
< lisa firstname "Lisa" >
< lisa sister maggy >
< maggy age 1 >
< maggy father homer >
…
The advantage of this representation is its simplicity and homogeneity, it leads to some practical observations:
- Finding the nodes: if the graph is defined through its arcs, the first question is to find the nodes. To answer this question, we need to consider the nature of the elements that make up the triples. Very clearly, these elements allow us to refer to the source and destination of each arc, and thus to the nodes of the graph. More precisely, they make it possible to distinguish the nodes between them and the arcs between each pair of nodes. They are therefore identifiers. The use of the same identifier thus refers to the same atom of knowledge represented. We can then ask for all the arcs coming out of a given node (i.e., all the triples having a certain identifier as a subject) or all the pairs of nodes linked by the same predicate (i.e., all the triples having a given identifier as a central element). There are languages for querying knowledge graphs in this way, and we will point in particular to SPARQL in the context of RDF.
- Symbolic scope of identifiers: it is important to recognise the purely symbolic, and therefore non-informative, scope of identifiers. Indeed, the representational capacity of a knowledge graph is limited to its structure. Put another way, renaming the nodes and arcs does not change the information content of the graph. Thus, we could easily choose the following renaming for our example:
< person1 firstname "Lisa" >
< person1 sister person2 >
< person2 age 1 >
< person2 father person3 >
…
So, the presence of a node person4 without any link in the graph does not bring us any additional information (Not even if it is indeed a person!). This does not prevent the clever choice of the identifiers used, but the informational significance of the choice of one symbol rather than another is outside the scope of the knowledge represented by the graph itself.
- Some limitations: the use of triples and identifiers to represent a graph has some limitations. For example, it prevents the consideration of isolated nodes, i.e. nodes that are neither the source nor the destination of any arc. As we have just seen, this limitation does not really take away from the expressiveness in the context of knowledge representation, except when one wants to question the presence or absence of a particular node. Similarly, two arcs between two given nodes cannot be decorated with the same identifier, otherwise the triples representing them would be indistinguishable. These limitations are neither good nor bad, but rather appropriate or not depending on the circumstances. As with all systems, there are limitations and it is simply a matter of knowing that they exist.
- About Data and object properties: in our example, an inconsistency seems to appear: the object of the triple
< homer age 38 >seems to be much more than a renameable identifier. Indeed, the node38comes with a specific semantics. These particular nodes correspond to literal values, also called constants. Coming with their own semantics (through a standard, e.g. the primitive data types in XML Schema), constants are not allowed to be described in the graph; we find the fact that the symbol refers to a knowledge outside the universe caught by the graph structure (phew… no inconsistency). This translates into nodes that cannot appear as triple subjects.
More precisely, there are two types of nodes: constants and object nodes. The former can only be used in the third position in triples. These triples describe what is called a data property of the subject node. The other nodes (such as Lisa, Maggy and Homer) have a different informational scope in the sense that they refer to strong elements of the represented knowledge universe. The triples with them in third position specify what is called an object property of the subject node; they are essential as they constitute the fabric of the actual structure of the modeled knowledge.
Old habits die hard...
Knowledge graphs provide a data model, a database implementing this model is called a triplestore. It is with this type of system that we will discuss in the second posts of this series. But before, let's look at how to embed a more traditional database (aka relational database with tables, relations as way to order the data) in a triplestore :
| firstname | age | father |
|---|---|---|
| Lisa | 8 | Homer |
| Maggy | 1 | Homer |
| Homer | 38 | Abraham |
| … | … | … |
Each tuple/row in such a table represents an entry which is described by the answer to different questions given in column/attribute. Thus, all entries in the same table are described in the same way. In this model, two rows answering all questions in the same way are not distinguishable. This distinction is forced by the presence of one or more attributes for which the answers will necessarily be different between two entries. This set of attributes is called the primary key. The primary key acts as an identifier and allows references to be made between tuples. This mechanism is called referential constraint. In our example, considering the firstname attribute as primary key, the father attribute allows each tuple to refer to another entry of the table to designate its father.
The translation to a knowledge graph is fairly straightforward: each tuple/row gives rise to the creation of a node in the graph, and each attribute/column to a specific predicate. Thus the boxes will each be translated into a data property triple whose subject will be the node associated with the tuple, the predicate will be that associated with the attribute, and the object will be the content of the box. The difficulty, if any, consists in translating the referential constraints into object properties. Thus, the preceding father attribute is in fact a reference to another row in the table (foreign key); these references will be translated as triples whose object will be the identifier of the referred tuple.
::: info This translation highlights a fundamental difference between the two approaches: where we choose to name the objects represented in knowledge graphs, the relational model invites us to identify these objects by their properties through the concept of primary key. The non-negligible consequences of this difference could be the subject of a post on its own…
:::
Conclusion
This first part was dedicated to the description of one of the cornerstones of explainable artificial intelligence technologies and Anabasis solutions: knowledge graphs. They provide a simple and homogeneous data model for systematic and high-level exploitation of your data. We have also seen how other existing technologies can be easily immersed in the world of data representation using graphs.
This presentation in this post is heavily weighted (by design) towards RDF. If you would like more information on the subject, we invite you to take a look at graph-oriented data models, including knowledge graphs in RDF. In particular, we can mention property graphs (e.g. from Oracle or neo4j) which, unlike RDF knowledge graphs, allow nodes and arcs to be decorated with attributes. A comparison between the two models is available here.
Antoine, scientific expert
and
Clément, chief technology officer
References
- [A] W.A. Woods, What's in a Link: Foundations for Semantic Networks, Bolt, Beranek and Newman, 1975
- [B] Chein, M., & Mugnier, M. (1992). Conceptual graphs: fundamental notions.
- [C] Sowa, J.F. (1983). Conceptual Structures: Information Processing in Mind and Machine.
- https://www.w3.org/2001/sw/
- https://www.w3.org/2001/sw/wiki/
Keywords : knowledge graphs, knowledge representation, RDF, triplestore, semantic web
Explainable AI in all its states (or almost!): a few use cases
2024 marks a turning point for Anabasis: after successful production launches with key customers, we needed to take a step back, beyond the sectoral or business applications of our Karnyx expla
Explainable artificial intelligence and Semantic Web tools - Part 2
In the previous post, we focused on RDF-style knowledge graphs, the basis of Anabasis technologies. Now we a
Retour sur la participation d'Anabasis à SemWeb.Pro 2023
Parce qu'Anabasis Assets a construit sa suite logicielle sur les normes et standards du web sémantique (entre autres), il était naturel de participer à la Jou