L'apprentissage automatique d'ontologie ou comment tous les textes cachent des schémas
Posté le 20/10/2023 par Anabasis
Traductions: enCatégories: Technologie
L'apprentissage automatique d'ontologie (ontology learning) à partir de textes permet de soutenir les ingénieurs de la connaissance dans l'analyse de la connaissance métier à partir des documents de l'entreprise. C'est un sujet d'innovation porteur chez Anabasis qui a initié un projet de thèse CIFRE en collaboration avec le CIAD. Venez en découvrir plus sur ce domaine d'innovation en IA hybride...
Un exemple vaut mieux qu'un long discours
Est-ce que vous vous rappelez du schéma du cycle de l'eau ?
L'eau de mer s'évapore. Cela crée de la vapeur d'eau qui se condense en nuage, qui se déversent sous forme de pluie...
Pour vous rafraichir la mémoire, voici un schéma tiré de Vikidia (l'encyclopédie pour les 8-13 ans) et la description correspondante :
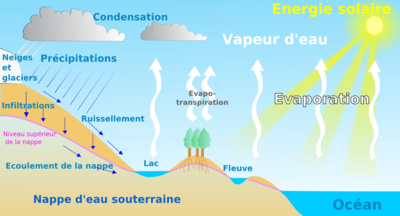
L'eau des océans et des mers, chauffée par le soleil, s'évapore : c'est ce que l'on appelle l'évaporation. Les lacs, cours d'eau ainsi que la plupart des terrains et leur végétation rejettent également de l'eau par évapotranspiration. Cette eau rejoint alors l'atmosphère sous forme de vapeur d'eau. L'air chaud et humide s'élève. En s'élevant, il se refroidit : les gouttes d'eau se regroupent pour former des nuages, c'est l'effet de la condensation. Cette eau, contenue dans les nuages, retombe sur les océans et les continents lors des pluies et des tombées de neige (précipitations).
Environ les trois quarts des précipitations se font sur les océans et les mers. Dans ce cas, le cycle de l'eau est très court. Quand l'eau tombe sur les continents, elle ruisselle ou s'infiltre dans le sol puis à travers les roches (infiltration ou écoulement souterrain). Une partie de cette eau tombée est utilisée par les plantes et ne s'écoule pas de cette façon. L'eau rejoint, dans un temps plus ou moins long, un cours d'eau. L'eau va de nouveau aller dans l'océan, les lacs et va reprendre le même chemin, ainsi c'est un cycle qui recommence à chaque fois.
Votre oeil a-t-il été attiré immédiatement par le schéma ? Vous êtes vous remémoré immédiatement la structure du cycle avec ses principaux composantes rien qu'à la vue des quelques éléments ? Avez-vous lu en diagonal le texte correspondant ? L'avez-vous lu tout court ?
Pourtant, le texte contenait exactement la même information que le schéma. C'est là toute la puissance des schémas : donner une compréhension visuelle et systémique d'un phénomène.
Et ce qui est vrai pour l'humain est vrai également pour les machines ! Grâce à la logique, les connaissances d'un domaine peuvent être modélisées dans une forme compréhensible à la fois par l'humain et par une machine : une ontologie ! Nous vous l'avons déjà expliqué ici.
Et pourtant, une grande partie de l'information qui nous parvient se trouve sous forme de textes : encyclopédie, journaux, règlementations, etc. Tous ces textes sont une mine d'informations sur notre monde, qui sont aujourd'hui très complexes à exploiter par des machines qui interprètent difficilement le langage humain (malgré les progrès des IA : ChatGPT ne permet pas encore de lire un texte et d'en déduire des instructions à donner à d'autres machines), ou même par les humains de par le volume de textes partagés chaque jour.
L'objectif de l'apprentissage automatique d'ontologie, c'est donc d'apprendre à la machine à construire des schémas à partir des textes. La machine serait ainsi capable de comprendre le texte du cycle de l'eau de telle sorte à reconstituer le schéma l’accompagnant (sans toute fois les aspects dessinés) avec les concepts (énergie solaire, océan, fleuve, lac, végétation, nuages) et leurs relations (évaporation, condensation, précipitation, infiltration, ruissellement).
Plus particulièrement, dans ce travail, nous nous intéressons à l'apprentissage de certains éléments de l'ontologie que l'on appelle les axiomes et les règles. Ce sont eux qui permettent de rendre l'ontologie opérationnelle en définissant des inférences : des cas d'application de certaines déduction.
Si nous reprenons l'exemple du cycle de l'eau, une précision sur l'évaporation pourrait être de lire: "L'eau s'évapore à partir de 100°C, dans les conditions de pression atmosphérique équivalente au niveau de la mer."
Cette phrase pourrait être transformé en son équivalent logique: "Température(eau) > 100°C ET Pression(atmosphère) = niveau-de-la-mer => Evaporation(eau)".
Cette information permettrait de définir le déclencheur d'un état de notre cycle, et donc de rendre le processus dynamique en pouvant prédire l'un des changements d'état.
Pourquoi en entreprise aussi on aime les schémas...
Vous me direz : Tout ça, c'est très bien pour les enfants, mais est-ce que ça a vraiment une utilité ailleurs qu'à école ? Quel est l'intérêt pour les entreprises ?
Dans les entreprises également, de nombreuses informations sont transmises sous la forme de documents divers qui s'ajoutent au fil des années, et dont le maintien et la transmission et la compréhension sont de véritables défis. Bien souvent, leur contenu serait mieux compris sous la forme de schémas. On le voit par la popularité des diagrammes UML, visualisations de processus, arbres de décision et autre logigrammes, ou tout simplement par les tableaux blancs de salle de réunion couverts de schémas divers dessinés à la hâte pour expliquer le fonctionnement d'un service à un nouveau collaborateur. Les cabinets de conseil le savent bien et font payer leurs services à prix d'or pour présenter leurs visualisations sous forme de schémas PowerPoint qui viendront s'ajouter à la masse d'informations existantes.
La promesse d'Anabasis est de rendre opérationnelle la connaissance métier de l'entreprise en donnant une interface commune à la compréhension métier (les humains), et à leurs implémentations dans les Systèmes d'Information (les machines). Cette promesse s’appuie sur une modélisation du domaine métier de l’entreprise, travail indispensable à la vue cohérente de l’ensemble. Ce travail long et minutieux est effectué par les ingénieurs de la connaissance grâce à deux volets qui ont été expliqués dans un billet précédent :
- la lecture des documents internes de l’entreprise
- l’interrogation des experts métiers
afin de capturer l’ensemble des informations explicites et implicites de l’entreprise.
L’ensemble de la documentation interne de l’entreprise est une manne d’informations qui mérite d’être exploitée à son plein potentiel et demande un temps et un investissement conséquent des ingénieurs de la connaissance. Une modélisation du domaine requiert aujourd’hui chez Anabasis environ 6 mois de travail à temps plein d’un ou deux ingénieurs de la connaissance pour être accomplie de bout en bout : des premières esquisses du domaine à la modélisation finale.
Cette manne pourrait être exploitée automatiquement de telle sorte à pré-définir une première ontologie qui pourrait être ensuite affinée et complétée par les ingénieurs de la connaissance lors des entretiens avec les experts. Ainsi, le temps et l'effort demandés pour la construction d'une nouvelle ontologie pourraient être réduits de manière conséquente, et cela permettrait aux ingénieurs de la connaissance de se focaliser sur les aspects les plus complexes de la modélisation.
La version longue pour ceux qui aiment entrer dans les détails...
L'apprentissage automatique d'ontologie (ontology learning) est l'objet d'étude de la thèse Combinaison d’approches de raisonnement par ontologie et machine learning pour l’aide à la construction d’ontologies qui a obtenu l'agrément de l'ANRT (Association Nationale Recherche Technologie) pour une durée de 3 ans dans le cadre du dispositif CIFRE (Convention Industrielle de Formation par la REcherche), en collaboration avec le laboratoire CIAD (Connaissance et Intelligence Artificielle Distribuée) de l'université de Bourgogne.
Ce domaine d’innovation est connu dans le champ scientifique en tant qu’ Ontology Learning ou Apprentissage automatique d’Ontologie en français dont les principes ont été posés dans l'exemple présenté plus haut. Un survol récent de ces techniques peut être trouvé dans [1, 2, 3].
Le domaine de l'ontology learning brasse un grand nombre de problématiques catégorisées suivant différents critères, qui répondent aux trois questions suivantes :
Quoi apprendre ? Cette première question lève le sujet essentiel du domaine en s’intéressant au but de l’apprentissage. Il a été proposé dans [4], de nombreuses fois repris par la suite, l’ontology learning layer cake (cf. Figure 1, directement reprise de [5]) présentant le processus d’apprentissage d’ontologie comme un empilement de sous-tâches de plus en plus complexes. Suivant l’application, l’ensemble de ces couches peut être considéré ou bien seulement une sous-partie.
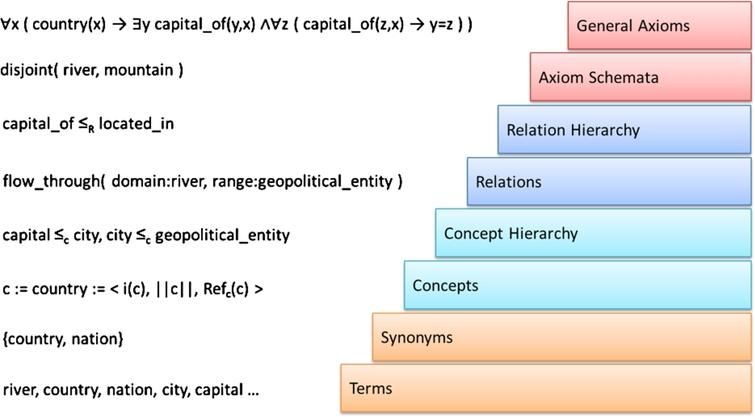
Apprendre des règles : le challenge que nous souhaitons adresser est celui de la construction automatique d’une ontologie formelle dite « heavyweight » [6, 1], c’est-à-dire visant les deux couches les plus hautes du layer cake (Figure 1). Ce sujet est clairement identifié dans la littérature comme un challenge majeur de la construction automatique d’ontologies, qui n’a été adressé que par une minorité d’articles et dont les résultats actuels sont considérés comme insuffisants [6, 7, 1, 2, 3].
A partir de quoi apprendre ? Les techniques d’apprentissage sont fondées en général sur une étude (semi-)automatisée d’une source pour laquelle le résultat est déjà connu ou, pour le moins, dont la qualité saurait être évaluée. On considère deux grandes classes de sources : des données non-structurées et des données (semi-)structurées. Dans le premier cas, l’information vient de façon brute et le processus d’apprentissage doit permettre de construire une structure à partir de l’étude des corrélations (ou de l’absence de corrélations) entre les données. Le type de source le plus envisagé dans les travaux sont les textes bruts. Dans le second cas, l’information utilisée arrive de façon organisée. Le processus d’apprentissage peut alors proposer une structure sémantique au-dessus de cette structure syntaxique initiale, induite par les corrélations et automatismes systématiques semblant régir les données sources. On rencontre ce cas lorsque les sources analysées sont de formats XML, JSON, CSV, etc. ou lorsqu’elles sont directement extraites de bases de données.
Apprendre à partir de données textuelles : Notre approche s'intéresse principalement aux données textuelles. Une très large majorité de la littérature de l’ontology learning est dédiée à la construction d’ontologies à partir de texte brut et montre que le sujet est d’actualité. Les techniques variées auxquelles ont abouti ces travaux ont été implémentées et intégrées dans des réalisations logicielles, références dans le domaine comme Text2Onto[8], OntoGain [9] ou OntoLearn [10]. D’autres techniques ont également été développées dans le cadre du natural language processing (NLP) et méritent une attention particulière. Cependant, parmi toutes ces techniques peu s’intéressent à la construction heavyweight.
Apprendre à partir de systèmes d’information : dans les projets Anabasis, les données textuelles (textes officiels, documentations, normes/standards, etc.) sont la plupart du temps accompagnées d’applications informatiques dont il est demandé une refonte ou une intégration à un système plus large. Malgré leurs défauts (modélisation incomplète, implémentation polluée par des contraintes techniques), les bases de données (MCD + contenu) associées à ces applications offrent une source alternative pour guider l’apprentissage d’ontologies.
Comment valider l’objet appris ? Un mécanisme d’apprentissage demande une fonction d’évaluation afin de le guider. [1] dénombre quatre types d’évaluation :
- Basée « golden standard » : comparaison avec une ontologie de référence idéale.
- Basée application : une utilisation typique de l’ontologie apprise dont le comportement est connu à l’avance, est préalablement définie et permet d’évaluer si l’ontologie apprise permet à l’application d’effectuer correctement sa mission.
- Dirigée par les données : cette évaluation est proche de l’évaluation golden standard mais ici la comparaison est faite à travers un corpus de données connu, avec lequel l’adéquation de l’ontologie apprise est évaluée.
- Humaine : cette méthode est basée sur la donnée d’un ensemble de critères permettant la sélection d’une ontologie parmi plusieurs candidats. Ces critères peuvent être définis de façon agnostique ou être liés au domaine appris.
Valider par l’existant (golden standard) : une partie importante des activités d’Anabasis consiste à concevoir des ontologies formalisant les tenants et aboutissants d’univers métier ; ces travaux ont été menés à la main à partir de données textuelles et de systèmes d’information existants. La validation de techniques de constructions automatiques d’ontologie peut profiter de ces réalisations par la mise en place de cas d’étude où l’objectif est de réapprendre les mêmes ontologies à partir des mêmes corpus de textes, et de comparer les résultats.
Notre hypothèse de travail est que l'identification dans les sources documentaires et les sources de données des constructions fondamentales des logiques formelles sous-jacentes aux ontologies (logiques de description) permettra de définir une modélisation du domaine sur l’ensemble des éléments de l’ontologie (termes, concepts, attributs, relations, contraintes et règles) avec d’une part une grande précision et d’autre part l’assurance d’une cohérence et d’une complétude formelles.
Une méthode d'identification des axiomes des logiques de description à partir de sources hétérogènes pourrait permettre de surmonter certains défis liés à la construction manuelle d'ontologies, tels que la difficulté à construire une ontologie complexe en partant de zéro et à maintenir sa cohérence au fil du temps. L’objectif à terme sera de concevoir un outil d’aide avancée à la construction d’ontologies formelles heavyweight, destinés aux ingénieurs de la connaissance.
Vers où allons nous ?
Ce travail de recherche en IA hybride (approches en Machine Learning et IA symbolique) a pour objectif d'automatiser une partie du travail des ingénieurs de la connaissance. Cela permettra entre autre de réduire significativement le temps dédié à chaque projet client, tout en assurant une homogénéité terminologique de l’ensemble des ontologies. La focalisation sur l’apprentissage des règles sera un élément différenciant pour Anabasis qui veut se positionner comme leader technologique sur le raisonnement, l’inférence et la prise de décision à partir des données de l’entreprise.
Pauline Armary,
Data Scientist chez Anabasis et doctorante au CIAD
Références :
[1] M. N. Asim, M. Wasim, M. U. G. Khan, W. Mahmood, H. M. Abbasi, A survey of ontology learning techniques and applications, Database 2018 (2018)
[2] F. N. Al-Aswadi, H. Y. Chan, K. H. Gan, Automatic ontology construction from text: a review from shallow to deep learning trend, Artificial Intelligence Review 53 (2020) pp 3901–3928.
[3] A. C. Khadir, H. Aliane, A. Guessoum, Ontology learning: Grand tour and challenges, Computer Science Review 39 (2021).
[4] BUITELAAR, Paul, CIMIANO, Philipp, et MAGNINI, Bernardo (ed.). Ontology learning from text: methods, evaluation and applications. IOS press, 2005.
[5] Ontology Learning and Population from Text. Springer US, 2006. https://doi.org/10.1007/978-0-387-39252-3.
[6] Wong, Wilson, Wei Liu, et Mohammed Bennamoun. « Ontology learning from text: A look back and into the future ». ACM Computing Surveys 44, no 4 (7 septembre 2012): 20:1-20:36. https://doi.org/10.1145/2333112.2333115.
[7] PETASIS, Georgios, KARKALETSIS, Vangelis, PALIOURAS, Georgios, et al. Ontology population and enrichment: State of the art. Knowledge-driven multimedia information extraction and ontology evolution, 2011, p. 134-166.
[8] Cimiano, Philipp, et Johanna Völker. « Text2Onto: a framework for ontology learning and data-driven change discovery ». In Proceedings of the 10th international conference on Natural Language Processing and Information Systems, 227‑38. NLDB’05. Berlin, Heidelberg: Springer-Verlag, 2005. https://doi.org/10.1007/11428817_21.
[9] Drymonas, Euthymios, Kalliopi Zervanou, et Euripides G. M. Petrakis. « Unsupervised Ontology Acquisition from Plain Texts: The OntoGain System ». édité par Christina J. Hopfe, Yacine Rezgui, Elisabeth Métais, Alun Preece, et Haijiang Li, 6177:277‑87. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer Berlin Heidelberg, 2010. https://doi.org/10.1007/978-3-642-13881-2_29.
[10] Navigli, Roberto, et Paola Velardi. « Learning Domain Ontologies from Document Warehouses and Dedicated Web Sites ». Computational Linguistics 30, no 2 (1 juin 2004): 151‑79. https://doi.org/10.1162/089120104323093276.
L’IA explicable dans tous ses états (ou presque !) : quelques cas d’application
2024 marque un tournant pour Anabasis : après de belles mises en production chez des clients clés, nous avions besoin de prendre un peu de recul, au-delà des applications sectorielles ou métie
Intelligence explicable avec les outils du Web sémantique - Partie 2
Dans le billet précédent, nous nous sommes concentrés sur les graphes de connaissances à la RDF, à
Retour sur la participation d'Anabasis à SemWeb.Pro 2023
Parce qu'Anabasis Assets a construit sa suite logicielle sur les normes et standards du web sémantique (entre autres), il était naturel de participer à la Jou