Intelligence explicable avec les outils du Web sémantique - Partie 2
Posté le 10/01/2024 par Anabasis
Traductions: enCatégories: Technologie
Dans le billet précédent, nous nous sommes concentrés sur les graphes de connaissances à la RDF, à la base des technologies Anabasis. Nous poursuivons avec les schémas de données qui permettent, pour le dire en quelques mots, de décrire l'organisation des graphes de connaissances.
Un chaos ordonné
L'utilisation du concept unique de triplet pour représenter l'information rend les graphes de connaissances très homogènes dans leur manipulation mais également très souples. Peut-être trop... Le modèle de données souffre en effet du défaut de ses avantages. D'un côté, cela autorise une liberté de représentation où les données sont directement mises en relation sans pré-requis à la description (en comparaison avec les tables des modèles relationnels à définir au prélable par exemple). D'un autre côté, l'absence de cadre autorise de faire tout et n'importe quoi. Cependant, ce désordre n'est en fait qu'apparent. En effet, exploiter un graphe de connaissances nécessite une certaine régularité dans la représentation afin de pouvoir traiter les données, ou ne serait-ce que pour en comprendre la logique.
A l'instar des autres modèles de données semi-structurés (XML, JSON, ...), les graphes de connaissances peuvent être munis d'un schéma de données, c'est-à-dire une sorte de contrat que doit vérifier la structure du graphe. Le schéma a alors deux rôles : (1) décrire l'organisation des données dans le graphe et donc permettre leur exploitation, mais aussi (2) valider la structure du graphe donné en vue de cette exploitation.
Schéma et modélisation
Notre objectif est de comprendre l'intérêt du schéma dans le cadre d'une modélisation où la donnée d'un graphe de connaissances décrit formellement une situation réelle avec ses entités et les relations entre ces entités. Dans ce contexte, la définition d'un schéma repose sur un principe :
les entités de même nature ont les mêmes caractéristiques.
Le schéma exprime ainsi en fonction de la nature d'une entité, les relations sémantiques attendues entre cette entité et le reste de l'univers représenté. Reprenons l'exemple de la description d'une famille par un graph de connaissances.
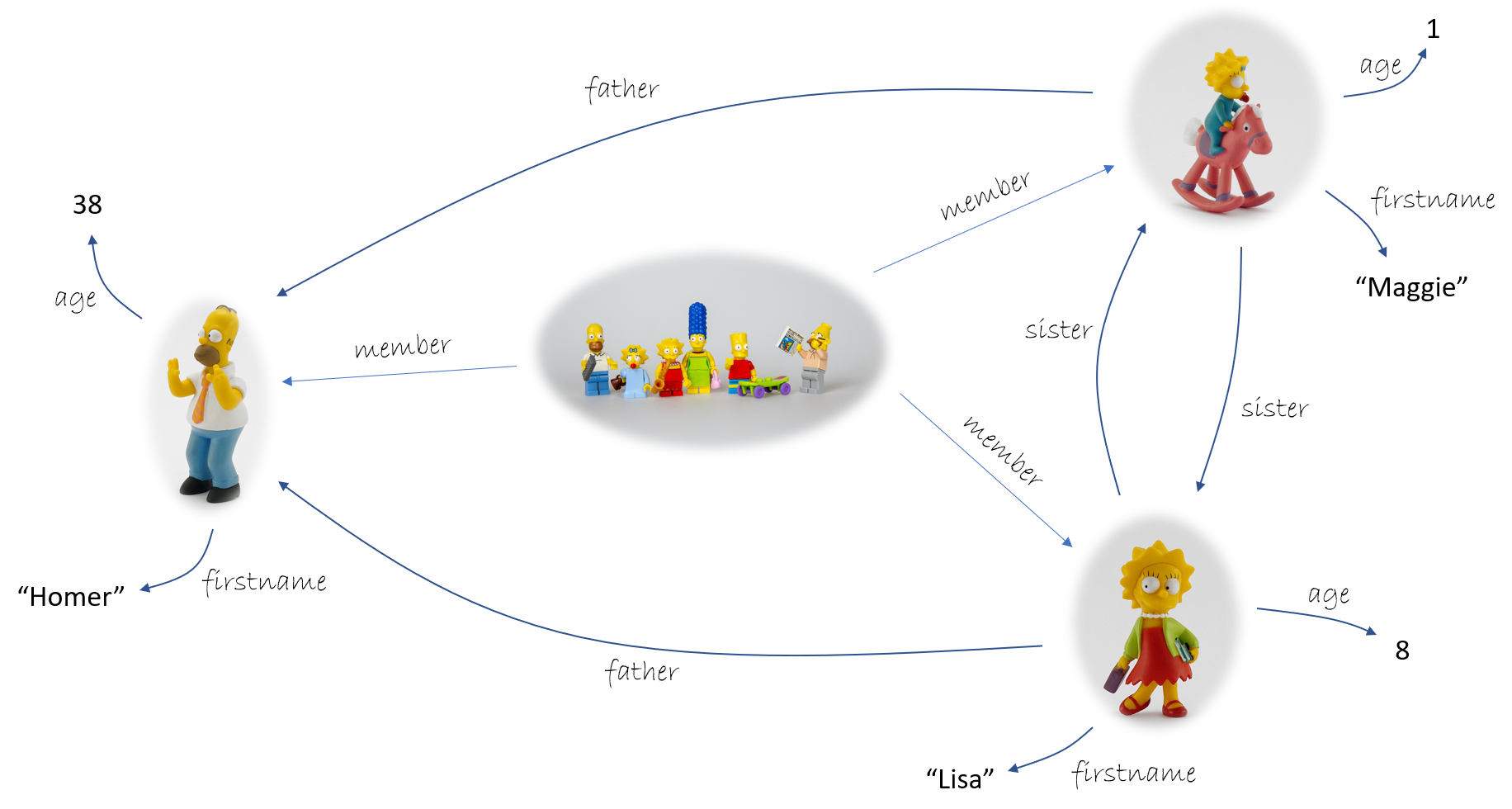
Si l'on prend le cas des arcs de prédicat member de ce graphe, on s'attend à ce que les triplets de la forme :
< ... member ... >
désignent tous de façon homogène la relation entre une famille et une personne appartenant à cette famille, car il s'agit effectivement du sens véhiculé par member. Et cela vaut pour tous les triplets : chaque nom de prédicat (2ème position dans les triplets - voir le billet précédent) identifie une catégorie complète de relations entre des sujets et des objets (1ère et 3ème positions du triplet).
L'exemple précédent se concentrait sur les arcs, mais le même principe s'applique aux nœuds. Dans l'exemple, on peut identifier la catégorie de toutes les personnes dont on peut remarquer que chaque élément possède un firstname et un age. A la différence de l'exemple de member qui est déjà présent dans le graphe de connaissances, les termes famille et personne en sont absents. Pour remédier à ce manque, on rajoutera des triplets de la forme suivante :
< lisa is_a Person >
< simpson is_a Family >
...
On remarque l'utilisation du nouvel (mais au combien important) identifiant is_a qui exprime l'apparatenance à une catéogie.
Donner le schéma des graphes de connaissances représentant des familles, ou plus généralement d'un ensemble de graphes de connaissances, consiste à énumérer l'ensemble des catégories de nœuds, des prédicats, et de toutes les contraintes de constructions que leur sémantique impose. Pour cela, une syntaxe est nécessaire.
L'écriture d'un schéma
Comme le schéma résume un ensemble de connaissances concernant la forme des graphes de connaissances que l'on souhaite manipuler, il peut être lui-même décrit à travers... un graphe de connaissances ! Pour illustrer cette construction, commençons par le cas très particulier du prédicat is_a précédent. Comme il permet de traduire la nature de l'entité représentée par un nœud, son objet sera une classe de nœuds (ou type ou concept suivant l'outil, le standard, ...). Cela nous donne nos premiers éléments du schéma : Family et Person sont des classes. Traduit en termes de triplets, cela donne :
< Family is_a Class >
< Person is_a Class >
On remarquera l'utilisation du prédicat is_a à nouveau. A partir de là, seule l'imagination présente un frein à l'écriture d'un schéma ! Par exemple :
< Family is_a Class >
< Person is_a Class >
< Student is_a Class >
< Student subClassOf Person >
< firstname is_a DataProperty >
< firstname domain Person >
< firstname range string >
< Family is_a Class >
< member is_a ObjectProperty >
< member domain Person >
< member range Family >
< age is_a DataProperty >
< age is_a FunctionalProperty >
< age domain Person >
< age range integer >
...
Bon, il faut être honnête, l'imagination mais surtout le sens que l'on met derrière tous ces nouvelles constructions (subClassOf, domain, range, etc.) et que l'on souhaite partagé par le plus grand nombre. En effet, qui dit syntaxe, dit sémantique. Listons rapidement les quelques constructions précédemment utilisées avec leurs significations :
-
Class, DataProperty et ObjectProperty : ces nœuds du schéma représentent les concepts de classe, de data property et d'object property dont nous avons déjà parlé. Ils apparaissent en objets du prédicat is_a (encore lui !) : il s'agit donc de classes. On sent venir l'existence d'un schéma des schémas pour veiller à ce qu'un schéma soit lui-même bien écrit. On entre ici dans l'univers (que nous ne ferons qu'évoquer...) des méta-modèles et de leur capacité (ou non) à s'auto-décrire.
-
domain et range spécifient les signatures des prédicats qui seront utilisés dans les graphes de connaissances considérés, c'est-à-dire les classes auxquelles doivent appartenir respectivement les sujets et objets qu'ils relient pour que leur usage soit valide. C'est ainsi que, dans notre exemple, les sujets de firstname seront des instances de la classe Person, les objets de member des instances de Family, etc.
-
subClassOf : la spécialisation est une construction classique en modélisation qui permet d'identifier l'existence d'une sous-catégorie d'instances au sein d'une classe. Dans l'exemple, il est spécifié que parmi les personnes il y a des étudiants. La construction n'en dit pas plus mais des contraintes spécifiques aux étudiants pourront maintenant être demandées (par ex., l'établissement dans lequel ils sont inscrits) en plus de celles imposées à toute personne.
-
FunctionalProperty : cette dernière construction contraint un prédicat à ne s'appliquer qu'une seule fois à un sujet donné. Ainsi, nous attendons que l'âge soit une propriété unique pour chaque personne, sans quoi il serait autorisé d'écrire à la fois < maggy age 1 > et < maggy age 2 > qui n'aurait que peu de sens quant à la sémantique naturelle endossée par l'identifiant age.
Il existe bien d'autres contraintes imaginables pour constituer un schéma. L'objectif ici n'est pas d'en faire une liste exhaustive mais simplement d'en transmettre la saveur, une saveur qui reste pour le moment assez informelle. C'est à ce moment que les standards entrent réellement en jeu ; ils fournissent la sémantique de ces constructions, c'est-à-dire leur sens précis, mathématique, de telle sorte que tout à chacun est capable d'interpréter correctement les attendus encodés dans un schéma.
Quelques standards
Les standards sont donc là pour cristalliser des consensus quant à des utilisations particulières des graphes de connaissances. Afin d'ouvrir un peu nos propos vers des technologies, voici quelques standards du Web Semantique par le W3C dédiés à l'écriture de schémas pour des graphes RDF.
-
RDF (pour Resource Description Framework) : Le standard RDF ne définit pas uniquement une certaine notion de graphe de connaissances mais propose également quelques constructions supplémentaires, notamment un début de vocabulaire. On y retrouve en particulier rdf:type (que nous avons appelé is_a plus haut) ou encore rdf:Property (la classe des symbole de prédicats). RDF propose également des constructions pour manipuler des séquences. Malgré tout, cela reste encore trop limité pour parler de schéma.
-
RDFS (pour RDF Schema) : Il s'agit d'une première extension minimale du vocabulaire RDF qui permet de retrouver la base des éléments introduits dans ce billet, notamment les notions de rdfs:class, rdfs:range, rdfs:domain, etc. Bien que très simple, la plupart des langages de description de structure RDF reposent sur RDFS, ce qui en fait un élément fondemental des outils du Web Semantique à la sauce RDF.
-
SHACL (pour Shapes Constraint Language) : Cette extension conséquente du vocabulaire RDFS a été conçue pour permettre la spécification d'un ensemble de contraintes sur la structure de graphes RDF. De ce point de vue, SHACL entre pleinement dans la notion de schéma telle que décrite plus haut. Ce langage repose sur la notion de shape qui décrit un attendu sur la forme que doit respecter localement un graphe de connaissances. On pourra par exemple exprimer la construction FunctionalProperty vue plus haut en demandant que tout noeud de classe Person ait au plus un arc sortant labellé par le prédicat age ; en SHACL : < cst_functional_age is_a PropertyShape > < cst_functional_age targetClass Person > < cst_functional_age path age > < cst_functional_age maxCount 1 >.
-
OWL (pour Web Ontology Language) : Cette autre extension de RDFS fournit les moyens de décrire un schéma RDF sous les traits d'une ontologie, même s'il ne s'agit pas de son but premier. En fait, une ontologie (formelle) permet de décrire un domaine d'intérêt à travers la donnée d'un ensemble de connaissances allant de ses éléments de base (individus), leurs relations, la description de ces relations, etc. Si on comprend ici les individus et leurs relations comme un graphe de connaissances RDF, la description de ces relations correspond à une conceptualisation de ce qui est représenté (identification des classes/concepts, des propriétés, et des contraintes associées). Ce qui écarte OWL des langages de spécfication de schémas RDF est qu'une ontologie vise à décrire le domaine d'intérêt et non les graphes représentant les instances. Néanmoins, la frontière est ténue et la modélisation d'un domaine (par une ontologie) est un excellent point de départ pour concevoir des outils métier (notamment des bases de données/connaissances) dans une approche MBSE.
Conclusion
La caractéristique première des modèles de données semi-structurées est de proposer un mécanisme de représentation pour lequel le schéma n'est pas un pré-requis. Leur propre structure suffit à organiser les données. Cependant, décrire par un schéma la façon dont la données est structurée sert à sa validation et à son exploitation par des outils informatiques. Nous avons vu que dans le cas des graphes de connaissances à la RDF, un schéma se présente assez naturellement sous la forme d'un système de typage qui repose sur l'identification de l'appartenance des éléments du graphe à certaines catégories. Pour ce qui est de RDF, différents standards permettent de spécifier un schéma (pour différents usages).
Les standards présentés offrent une syntaxe pour décrire comment contraindre la forme d'une classe de graphes de connaissances d'intérêt. Cependant, passer de la sémantique de cette syntaxe (parfois donnée de façon semi-formelle, voire informelle) à un outil opérationnel vérifiant effectivement si les contraintes sont vérifiées par un graphe donné n'est pas une tâche simple. Dans les prochains billets, nous rentrerons dans le monde des règles logiques et des moteurs de raisonnement qui apportent une solution à cette question ; nous verrons également leur intérêt en modélisation et comment ils permettent de lier base de données et raisonnement.
Antoine, expert scientifique
L’IA explicable dans tous ses états (ou presque !) : quelques cas d’application
2024 marque un tournant pour Anabasis : après de belles mises en production chez des clients clés, nous avions besoin de prendre un peu de recul, au-delà des applications sectorielles ou métie
Retour sur la participation d'Anabasis à SemWeb.Pro 2023
Parce qu'Anabasis Assets a construit sa suite logicielle sur les normes et standards du web sémantique (entre autres), il était naturel de participer à la Jou
L'apprentissage automatique d'ontologie ou comment tous les textes cachent des schémas
L'apprentissage automatique d'ontologie (ontology learning) à partir de textes permet de soutenir les ingénieurs de la connaissance dans l'analyse de la connaissance métier à partir des documen