Automatic ontology learning or how all texts hide schemas
Posted on 2023-10-20 by Anabasis
Translations: frCategories: Technology
Text-based automatic ontology learning supports knowledge engineers in analysing business knowledge from company documents. This is a promising area of innovation at Anabasis, which has initiated a CIFRE thesis project in collaboration with CIAD. Find out more about this area of innovation in hybrid AI...
An example is worth a thousand words
Do you remember the diagram of the water cycle?
Seawater evaporates. This creates water vapour, which condenses into clouds that pour down as rain...
To refresh your memory, here's a diagram from Wikipedia in Simple English and the corresponding description:
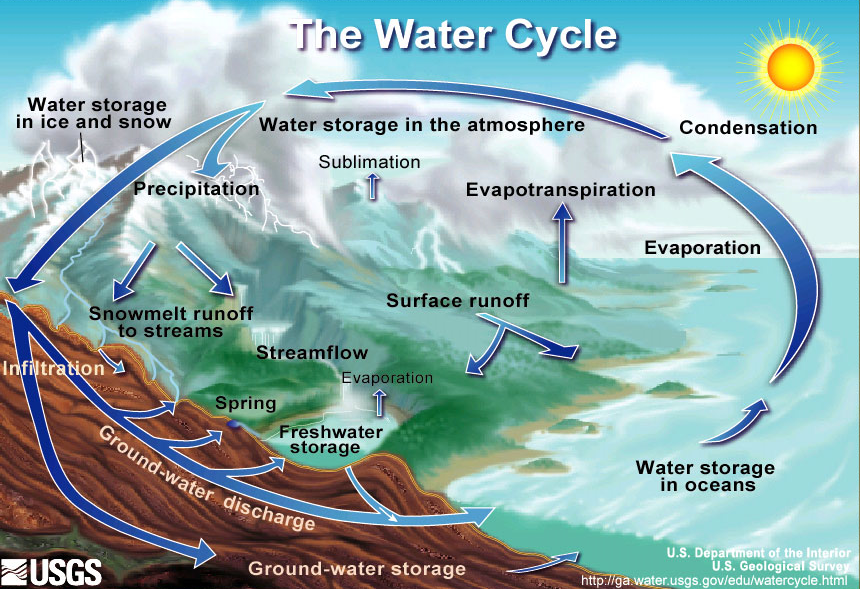
This is the process that water starts and ends in the water cycle.
- The cycle starts when water on the surface of the Earth evaporates. Evaporation means the sun heats the water which turns into a gas.
- Then, water collects as water vapour in the sky. This makes clouds.
- Next, the water in the clouds gets cold. This makes it become liquid again. This process is called condensation.
- Then, the water falls from the sky as rain, snow, sleet or hail. This is called precipitation.
- The water sinks into the surface and also collects into lakes, oceans, or aquifers. It evaporates again and continues the cycle.
- This whole process in which water evaporate and falls on the land and later flows back in river and pond is known as water cycle.
Was your eye was immediately drawn to the diagram ? Did you remember the structure of the cycle with its main components just by looking at the overall scheme ? Did you skim over the text ? Did you read it at all ?
Yet the text contains exactly the same information as the diagram. That's the power of diagrams: to give a visual and systemic understanding of a phenomenon.
And what's true for humans holds also for machines! Thanks to logic, the knowledge of a domain can be modelled in a form that can be understood by both humans and machines: an ontology! We've already explained this here.
And yet, a large proportion of the information we receive is in the form of texts: encyclopaedias, newspapers, regulations, etc. All these texts are a mine of information about our world, which are very complex to exploit by machines that have difficulty interpreting human language (despite advances in AI: ChatGPT cannot yet read a text and deduce instructions to give to other machines), or even by humans because of the volume of texts shared every day.
The aim of automatic ontology learning is therefore to teach the machine to construct diagrams from texts. The machine would thus be able to understand the text on the water cycle in such a way as to reconstitute the accompanying diagram (without, however, the aspects drawn) with the concepts (solar energy, ocean, river, lake, vegetation, clouds) and their relationships (evaporation, condensation, precipitation, infiltration, runoff).
More specifically, in this work we are interested in learning certain elements of the ontology known as axioms and rules. Thanks to them, it is possible to make the ontology operational by defining inferences: cases of application of certain deductions.
If we take the example of the water cycle again, a statement about evaporation might read: "Water evaporates from 100°C, under conditions of atmospheric pressure equivalent to sea level".
This sentence could be transformed into its logical equivalent: "Temperature(water) > 100°C AND Pressure(atmosphere) = sea-level => Evaporation(water)".
This information would make it possible to define the trigger for a state in our cycle, and therefore to make the process dynamic by being able to predict one of the changes of state.
Why we like diagrams in business too...
You might wonder: that's all very well for children, but is it really useful anywhere other than school? What's in it for companies?
In companies too, a lot of information is passed on in the form of various documents that are added to over the years, and which are a real challenge to maintain, pass on and understand. Very often, their content would be better understood in the form of diagrams. We can see this in the popularity of UML diagrams, process visualisations, decision trees and other flowcharts, or quite simply in the whiteboards in meeting rooms covered with various diagrams hastily drawn to explain the workings of a department to a new employee. Consultancy firms are well aware of this, and charge top dollar for their services to present their visualisations in the form of PowerPoint diagrams that will be added to the mass of existing information.
The promise of Anabasis is to make the company's business knowledge operational by providing a common interface for business understanding (humans) and their implementation in Information Systems (machines). This promise is based on the modelling of the company's business domain, which is essential for a coherent overall view. This long and meticulous work is carried out by knowledge engineers, using two methods that were explained in a previous post:
- reading the company's internal documents
- interviewing business experts
in order to capture all of the company's explicit and implicit information.
All of the company's internal documentation is a wealth of information that deserves to be exploited to its full potential, and requires a significant investment of time by knowledge engineers. At Anabasis, modelling a domain currently requires around 6 months' full-time work by one or two knowledge engineers to be completed from start to finish: from the first sketches of the domain to the final model.
This resource could be used automatically to pre-define an initial ontology which could then be refined and added to by knowledge engineers during interviews with experts. In this way, the time and effort required to build a new ontology could be significantly reduced, allowing knowledge engineers to focus on the most complex aspects of modelling.
The long version for those who like to go into details...
Automatic ontology learning is the subject of a thesis entitled Combining ontology-based reasoning and machine learning approaches to aid ontology construction, which has been approved by the ANRT (Association Nationale Recherche Technologie) for a period of 3 years as part of the CIFRE (Convention Industrielle de Formation par la REcherche) scheme, in collaboration with the CIAD (Connaissance et Intelligence Artificielle Distribuée) laboratory at the University of Burgundy.
This area of innovation is known in the scientific field as Ontology Learning, the principles of which were set out in the example above. A recent overview of these techniques can be found in [1, 2, 3].
The field of ontology learning encompasses a large number of problems categorised according to different criteria, which answer the following three questions:
Learning What ? This first question raises the essential issue of the field by focusing on the purpose of learning. The ontology learning layer cake (see Figure 1, taken directly from [5]) was proposed in [4] and has been used many times since, presenting the ontology learning process as a stack of increasingly complex sub-tasks. Depending on the application, the whole of these layers may be considered, or just a sub-part.
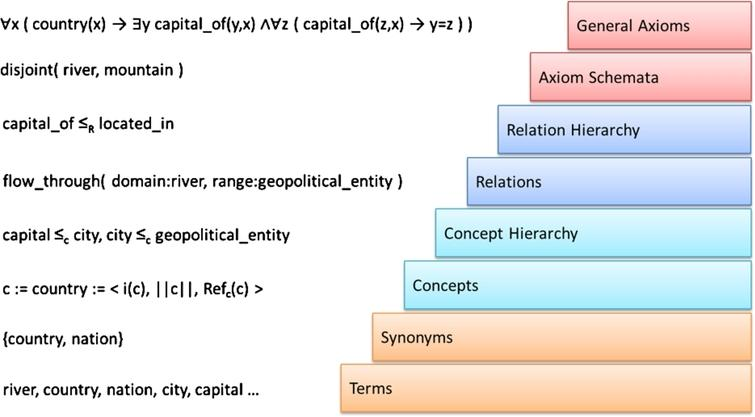
Learning rules: the challenge we want to address is the automatic construction of a "heavyweight" formal ontology [6, 1], i.e. targeting the top two layers of the layer cake (Figure 1). This subject is clearly identified in the literature as a major challenge in the automatic construction of ontologies, which has only been addressed by a minority of articles and whose current results are considered insufficient [6, 7, 1, 2, 3].
Learning from What ? Learning techniques are generally based on a (semi-)automated study of a source for which the result is already known or, at the very least, whose quality can be assessed. There are two main classes of source: unstructured data and (semi-)structured data. In the first case, the information comes in raw form, and the learning process should enable a structure to be constructed from the study of correlations (or the absence of correlations) between the data. The type of source most often considered in research is raw text. In the second case, the information used is organised. The learning process can then propose a semantic structure above this initial syntactic structure, induced by the correlations and systematic automatisms that seem to govern the source data. This is the case when the sources analysed are in XML, JSON, CSV format, etc. or when they are extracted directly from databases.
Learning from textual data : Our approach focuses mainly on textual data. The vast majority of the ontology learning literature is devoted to the construction of ontologies from plain text, which shows that the subject is a topical one. The various techniques that have emerged from this work have been implemented and integrated into leading software applications such as Text2Onto [8], OntoGain [9] and OntoLearn [10]. Other techniques have also been developed in the context of natural language processing (NLP) and deserve particular attention. However, few of these techniques are concerned with heavyweight construction.
Learning from information systems: in Anabasis projects, textual data (official texts, documentations, norms/standards, etc.) are most often accompanied by IT applications which are asked to be redesigned or integrated into a larger system. Despite their shortcomings (incomplete modelling, implementation polluted by technical constraints), the databases (schema + content) associated with these applications offer an alternative source to guide ontology learning.
How to evaluate ? A learning mechanism requires an evaluation function to guide it. [1] identifies four types of evaluation:
- Based on "golden standards": comparison with an ideal reference ontology.
- Application-based: a typical use of the learned ontology, whose behaviour is defined in advance and used to assess whether the learned ontology enables the application to carry out its mission correctly.
- Data-driven: this evaluation is close to the standard golden evaluation, but here the comparison is made through a known corpus of data, with which the suitability of the learned ontology is evaluated.
- Human: this method is based on a set of criteria for selecting an ontology from several candidates. These criteria can be defined agnostically or be linked to the learned domain.
Validating using existing data (golden standard): a major part of Anabasis' activities consists in designing ontologies that formalise the ins and outs of business universes; this work has been carried out manually using existing textual data and information systems. The validation of automatic ontology construction techniques can benefit from these achievements by setting up case studies where the aim is to relearn the same ontologies from the same text corpora, and to compare the results.
Our working hypothesis is that identifying the fundamental constructs of the formal logics underlying ontologies (description logics) in documentary sources and data sources will make it possible to define a modelling of the domain based on all the elements of the ontology (terms, concepts, attributes, relations, constraints and rules) with a high degree of precision and the assurance of formal consistency and completeness.
A method for identifying the axioms of description logics from heterogeneous sources could make it possible to overcome certain challenges associated with the manual construction of ontologies, such as the difficulty of building a complex ontology from scratch and maintaining its consistency over time. The ultimate aim will be to design an advanced tool to help build heavyweight formal ontologies, for use by knowledge engineers.
Where are we heading?
The aim of this research work in hybrid AI (Machine Learning and symbolic AI approaches) is to automate part of the work of knowledge engineers. Among other things, this will significantly reduce the time spent on each customer project, while ensuring terminological consistency across all ontologies. The focus on rule learning will be a key differentiator for Anabasis, which aims at positionning itself as a technological leader in reasoning, inference and decision-making based on enterprise data.
Pauline Armary,
Data Scientist at Anabasis et PhD Student at CIAD
References :
[1] M. N. Asim, M. Wasim, M. U. G. Khan, W. Mahmood, H. M. Abbasi, A survey of ontology learning techniques and applications, Database 2018 (2018)
[2] F. N. Al-Aswadi, H. Y. Chan, K. H. Gan, Automatic ontology construction from text: a review from shallow to deep learning trend, Artificial Intelligence Review 53 (2020) pp 3901–3928.
[3] A. C. Khadir, H. Aliane, A. Guessoum, Ontology learning: Grand tour and challenges, Computer Science Review 39 (2021).
[4] BUITELAAR, Paul, CIMIANO, Philipp, et MAGNINI, Bernardo (ed.). Ontology learning from text: methods, evaluation and applications. IOS press, 2005.
[5] Ontology Learning and Population from Text. Springer US, 2006. https://doi.org/10.1007/978-0-387-39252-3.
[6] Wong, Wilson, Wei Liu, et Mohammed Bennamoun. « Ontology learning from text: A look back and into the future ». ACM Computing Surveys 44, no 4 (7 septembre 2012): 20:1-20:36. https://doi.org/10.1145/2333112.2333115.
[7] PETASIS, Georgios, KARKALETSIS, Vangelis, PALIOURAS, Georgios, et al. Ontology population and enrichment: State of the art. Knowledge-driven multimedia information extraction and ontology evolution, 2011, p. 134-166.
[8] Cimiano, Philipp, et Johanna Völker. « Text2Onto: a framework for ontology learning and data-driven change discovery ». In Proceedings of the 10th international conference on Natural Language Processing and Information Systems, 227‑38. NLDB’05. Berlin, Heidelberg: Springer-Verlag, 2005. https://doi.org/10.1007/11428817_21.
[9] Drymonas, Euthymios, Kalliopi Zervanou, et Euripides G. M. Petrakis. « Unsupervised Ontology Acquisition from Plain Texts: The OntoGain System ». édité par Christina J. Hopfe, Yacine Rezgui, Elisabeth Métais, Alun Preece, et Haijiang Li, 6177:277‑87. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer Berlin Heidelberg, 2010. https://doi.org/10.1007/978-3-642-13881-2_29.
[10] Navigli, Roberto, et Paola Velardi. « Learning Domain Ontologies from Document Warehouses and Dedicated Web Sites ». Computational Linguistics 30, no 2 (1 juin 2004): 151‑79. https://doi.org/10.1162/089120104323093276.
Explainable AI in all its states (or almost!): a few use cases
2024 marks a turning point for Anabasis: after successful production launches with key customers, we needed to take a step back, beyond the sectoral or business applications of our Karnyx expla
Explainable artificial intelligence and Semantic Web tools - Part 2
In the previous post, we focused on RDF-style knowledge graphs, the basis of Anabasis technologies. Now we a
Retour sur la participation d'Anabasis à SemWeb.Pro 2023
Parce qu'Anabasis Assets a construit sa suite logicielle sur les normes et standards du web sémantique (entre autres), il était naturel de participer à la Jou